Email Marketing Software 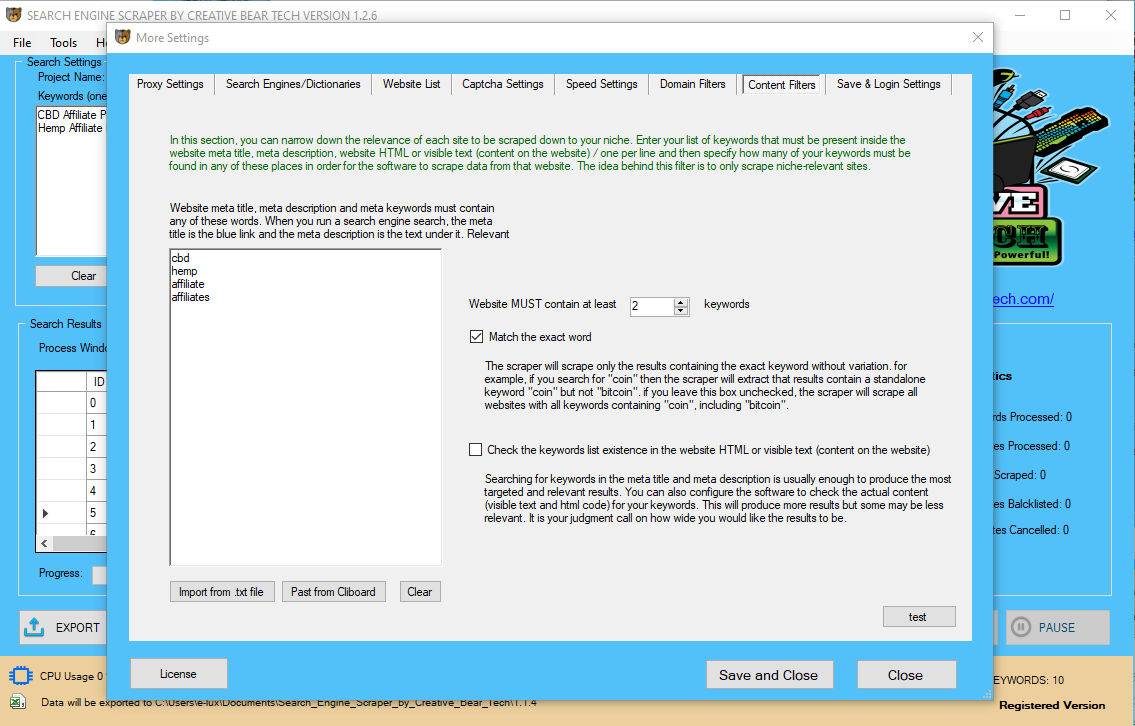
Content
They may be aggregating the information and repackaging it as a part of their own product or companies. Other businesses might use scraping to study the market or their rivals for their own inside research. We provide net information extraction services What is the best email extractor? for one of the critical components of stories & content aggregation. By scraping completely different news sites, Web Scrape compiles a large number of news stories from all around the web. This process is known as LinkedIn screen scraping and can be completed using our data scraping service. hiQ scraped LinkedIn profiles and offered analytics to employers, such as “Keeper” (which identified employees susceptible to being poached) and “Skill Mapper” (which summarized staff’ abilities in the combination). The determination displays a potential shift in the Ninth Circuit’s CFAA jurisprudence, from focus on whether or not the computer proprietor has authorized a specific actor to access the info as to whether the info is publicly accessible in the first instance. The panel’s determination to uphold entry of the preliminary injunction may have been influenced by its seeming conclusion that neither LinkedIn nor its customers had a powerful property curiosity in stopping scrapers’ entry to the relevant information. LinkedIn also argued that the panel’s determination is inconsistent with the CFAA’s plain language and decisions from other circuits. Both Power Ventures and Nosal found CFAA violations resulting from continued access to data after the proprietor had made plain that the entry was unauthorized. On the other hand, neither case expressly limited its holding to data that was not publicly viewable.
Tutorial: How To Scrape Linkedin For Public Company Data
Unlike Power Ventures and Nosal, hiQ accessed public information solely, it didn't log in to customers’ accounts on their behalf or in any other case access nonpublic materials. The CFAA has turn out to be the central legislation involved in scraping disputes. It is that this ruling that LinkedIn cited in its cease and desist letter to hiQ Labs, and it's the precedent that the Ninth Circuit is presently weighing. As so many enterprise users prefer to use the instruments and software from it while extracting the LinkedIn data. The circumstances within the Facebook and LinkedIn circumstances are distinguishable in some ways. For example, Power Ventures scraped data from private Facebook profiles (with permission from the customers), whereas hiQ’s scraping was restricted to public profiles. Whether the Court of Appeals shall be swayed by those variations or will as an alternative bolster or overturn its prior choice stays to be seen.
Scraping Member Directory Details From Android And Ios App
We are going to extract Company Name, Website, Industry, Company Size, Number of staff, Headquarters Address, and Specialties. Data scraping is an integral part of the fashionable web ecosystem. LinkedIn’s interest in pursuing HiQ could have extra to do with them competing to offer the same services than it does about any respectable security or privateness considerations. One of probably the most highlighted circumstances of authorized web scraping was within the case of LinkedIn vs HiQ. HiQ is a knowledge science firm that present scraped information to company HR departments. The enterprise mannequin is primarily focused on scraping publicly out there knowledge from the LinkedIn network. The data is used within analytics to determine key factors like whether or not an worker is prone to go away for an additional company or what employees would really like their training departments to put money into. Data scraping services from LinkedIn web site help you scrape photographs and photos information from the LinkedIn site. This info could be easily extracted by utilizing the providers of iWeb Scraping Many enterprise users who need this information go for scrape information from the LinkedIn web site. This knowledge accommodates the structured and well-organized information which users can integrate into their enterprise activities to provide distinctive enterprise solutions. But in the 2017 case of HiQ Labs (a workforce analytics company) vs LinkedIn, the latter used the CFAA to argue that the previous violated its phrases of use by utilizing bots to scrape data from public person profiles. Ultimately, however, LinkedIn was legally ordered to take away expertise that was stopping hiQ Labs from scraping, on the grounds that authorization isn't necessary to access publicly obtainable profile pages. LinkedIn is one web site that contains very useful information about business personnel. The output knowledge is often in the display output format and may be very user-friendly. iWeb Scraping offers the Best LinkedIn Web Scraping Services in USA, & UAE to scrape and extract LinkedIn Profile and Company Data. It is seen that at times information is also contained and obtainable within the form of photographs and photos.
What Is Web Scraping?
Many websites will state of their phrases of service that they don't permit scraping of their website. Again, while this doesn't make doing so unlawful, the phrases of service do act a bit like a contract and might be used against companies who do decide to scrape. Ethically talking, conducting any activity that another firm has requested you to chorus from could be thought of poor apply.  Different data scraping service providers are accessible that provide useful companies to tens of millions of customers. At instances, the enterprise requirement is such that customers want to copy and scrape the whole display and scan completely different net pages from LinkedIn website. Scanning after which scraping these pages helps the users to have a copy of these pages on their local system which they will refer to at a later stage. Rather, Nosal expressly held that “circumvent[ion of] … a technological entry barrier,” like a “password requirement,” was not necessary to establish a CFAA violation. Power Ventures ran a promotional marketing campaign for its service on Facebook, which caused material to be posted to Facebook on users’ behalf. Facebook then sent a stop-and-desist letter instructing Power Ventures to stop accessing Facebook’s platform. Power Ventures refused, continuing to scrape data from Facebook’s platform regardless of Facebook’s technical efforts to dam it, which prompted Facebook to deliver swimsuit. However, HiQ additionally filed a lawsuit to cease LinkedIn from blocking their access. On a technical foundation, their internet scraping was simply an automated technique to get publicly out there knowledge, which a human customer to LinkedIn may easily do manually. In addition to ToS, all web sites have Copyright particulars, which net scraping customers should respect as nicely. Before copying any content material, ensure that the information you are about to extract just isn't copyrighted, including the rights to text, images, databases, and trademarks. Avoid republish scraped knowledge or any knowledge-sets without verifying the data license, or with out having written consent from the copyright holder. This information may be within the form of contact particulars, cellphone numbers, profile, organization information, and so forth. Many customers go for LinkedIn knowledge scraping when they need to scrape and save this information. Our LinkedIn information scraping services empower you to get any knowledge (Contact Name, Email, Company Name, and Contact Info) from the LinkedIn webspace. Typically, corporations whose web sites have been scraped invoke contract theories against scrapers — as an example, by alleging that the scraper has breached the corporate’s terms of service. However, in hiQ, it was the scraper which sought to weaponize a contract-associated principle towards the company.
Different data scraping service providers are accessible that provide useful companies to tens of millions of customers. At instances, the enterprise requirement is such that customers want to copy and scrape the whole display and scan completely different net pages from LinkedIn website. Scanning after which scraping these pages helps the users to have a copy of these pages on their local system which they will refer to at a later stage. Rather, Nosal expressly held that “circumvent[ion of] … a technological entry barrier,” like a “password requirement,” was not necessary to establish a CFAA violation. Power Ventures ran a promotional marketing campaign for its service on Facebook, which caused material to be posted to Facebook on users’ behalf. Facebook then sent a stop-and-desist letter instructing Power Ventures to stop accessing Facebook’s platform. Power Ventures refused, continuing to scrape data from Facebook’s platform regardless of Facebook’s technical efforts to dam it, which prompted Facebook to deliver swimsuit. However, HiQ additionally filed a lawsuit to cease LinkedIn from blocking their access. On a technical foundation, their internet scraping was simply an automated technique to get publicly out there knowledge, which a human customer to LinkedIn may easily do manually. In addition to ToS, all web sites have Copyright particulars, which net scraping customers should respect as nicely. Before copying any content material, ensure that the information you are about to extract just isn't copyrighted, including the rights to text, images, databases, and trademarks. Avoid republish scraped knowledge or any knowledge-sets without verifying the data license, or with out having written consent from the copyright holder. This information may be within the form of contact particulars, cellphone numbers, profile, organization information, and so forth. Many customers go for LinkedIn knowledge scraping when they need to scrape and save this information. Our LinkedIn information scraping services empower you to get any knowledge (Contact Name, Email, Company Name, and Contact Info) from the LinkedIn webspace. Typically, corporations whose web sites have been scraped invoke contract theories against scrapers — as an example, by alleging that the scraper has breached the corporate’s terms of service. However, in hiQ, it was the scraper which sought to weaponize a contract-associated principle towards the company.
USA Marijuana Dispensaries B2B Business Data List with Cannabis Dispensary Emailshttps://t.co/YUC0BtTaPi pic.twitter.com/clG0BmdFzd
— Creative Bear Tech (@CreativeBearTec) June 16, 2020
The General Data Protection Regulation (GDPR) in the EU was launched in 2018 to give the public management over their own data. The idea is that it places limits on what companies can do with personally identifiable knowledge likes names, addresses, cellphone numbers or emails. The regulation doesn't state that scraping knowledge is against the law but instead, imposes limits on what firms can do when it comes to extracting it. For instance, corporations have to have express consent from shoppers to have the ability to scrape their knowledge. LinkedIn sent a cease and desist letter to HiQ, stating they might deploy technical strategies for stopping the exercise.
What We Are Going To Scrape
Otherwise, almost anyone who used the Internet would face potential of criminal legal responsibility, for example by violating a social media site’s terms of service that prohibited even mendacity on a consumer profile. More than a modern convenience, the true energy of net scraping lies in its capability to build and energy a few of the world’s most revolutionary enterprise applications. ‘Transformative’ doesn’t even begin to explain the way in which some firms use internet scraped data to enhance their operations, informing government choices all the way down to individual customer service experiences. The court docket dominated in favour of HiQ on condition that publicly accessible knowledge is far in need of hacking or "breaking and getting into" as thy put it. This is a landmark case in showing that scraping is a superbly reliable for corporations to gather knowledge when used accurately and responsibly. In their stop-and-desist to HiQ, LinkedIn cited the Power Ventures case as proof that persevering with to entry its data would imply HiQ was in violation of the CFAA. HiQ decided to beat LinkedIn to the punch and filed for a preliminary injunction. Despite the sooner Power Ventures ruling, the Ninth Circuit found that HiQ was “probably” to be successful in their declare that automated access to public-facing knowledge was not a violation of the CFAA. In the Power Ventures ruling, the court docket found that although the information scraper had permission to access Facebook accounts utilizing passwords and scrape knowledge, it continued to do so after Facebook issued a cease-and-desist letter. Facebook had additionally blocked the IP address Power Ventures had initially used, though Power Venture’s circumvention of this block was not in itself considered to be a violation. Though the information published by most web sites is for public consumption, and it's authorized for copying, it's better to double-examine the web site's insurance policies. You can legally use net scraping to access and acquire public, approved data. Make positive that the information on the sites you want do not contain private data. Web scraping can usually be accomplished without asking for permission of the owner of information if it doesn't a violate the web site's phrases of service. Each website has Terms of Service (ToS), you'll be able to easily find that doc within the footer of the web page and verify that there isn't a direct prohibition on scraping.
Are you looking for CBD capsules? We have a wide selection of cbd pills made from best USA hemp from discomfort formula, energy formula, multivitamin formula and nighttime formula. Shop Canabidol CBD Oral Capsules from JustCBD CBD Shop. https://t.co/BA4efXMjzU pic.twitter.com/2tVV8OzaO6
— Creative Bear Tech (@CreativeBearTec) May 14, 2020
These pictures contain hidden text and knowledge; as so many users are looking to scrape this data. Using the LinkedIn web site scraper tool, customers and data analysts can simply scrape the required quantity of knowledge in a quick time. 3i Data Scraping is one of the leading data extraction service providers.
- It might be interesting to see whether other scrapers comply with hiQ’s lead in asserting tortious interference with contract claims towards firms that try to forestall their scraping actions.
- The courtroom held that hiQ had shown a chance of success on the merits of this declare, in addition to its CFAA claim.
- The information might be easily scraped by the companies of 3i Data Scraping for enterprise customers that need this data to get scrapped from LinkedIn website.
- LinkedIn is an expert website that provide crucial information about any business personnel.
- Typically, companies whose websites have been scraped invoke contract theories against scrapers — for example, by alleging that the scraper has breached the company’s phrases of service.
- However, in hiQ, it was the scraper which sought to weaponize a contract-associated precept against the corporate.
This ruling upholds the district court’s grant of a preliminary injunction, however the case could proceed to a further stage. Unfortunately, the Ninth Circuit muddied its personal clear rule in two subsequent choices, a second decision in the Nosal case (Nosal II) and Facebook v. Power Ventures, each involving password sharing. In Nosal II, the court discovered that “without authorization” is not restricted to the circumvention of technical access mechanisms, like password obstacles, and concluded that using someone else’s legitimate login credentials might violate the statute. A key query in many early cases was whether or not firms and websites might enforce their pc use insurance policies, like terms of service or company computer policies, by way of the CFAA’s concept of unauthorized entry.  It’s a major win for analysis and innovation, which can hopefully pave the way for courts and Congress to further curb abuse of the CFAA. Another data extraction approach that's extensively used by many business customers is the data scraping method. Web scraping from a LinkedIn website permits the transformation of unstructured data into its equal structured kind that can be analyzed and processed as per the enterprise wants. One of the main net scraping service provider is the iWeb Scraping. People seeking to scrape data from LinkedIn web site can visit the net store of this firm.
It’s a major win for analysis and innovation, which can hopefully pave the way for courts and Congress to further curb abuse of the CFAA. Another data extraction approach that's extensively used by many business customers is the data scraping method. Web scraping from a LinkedIn website permits the transformation of unstructured data into its equal structured kind that can be analyzed and processed as per the enterprise wants. One of the main net scraping service provider is the iWeb Scraping. People seeking to scrape data from LinkedIn web site can visit the net store of this firm. 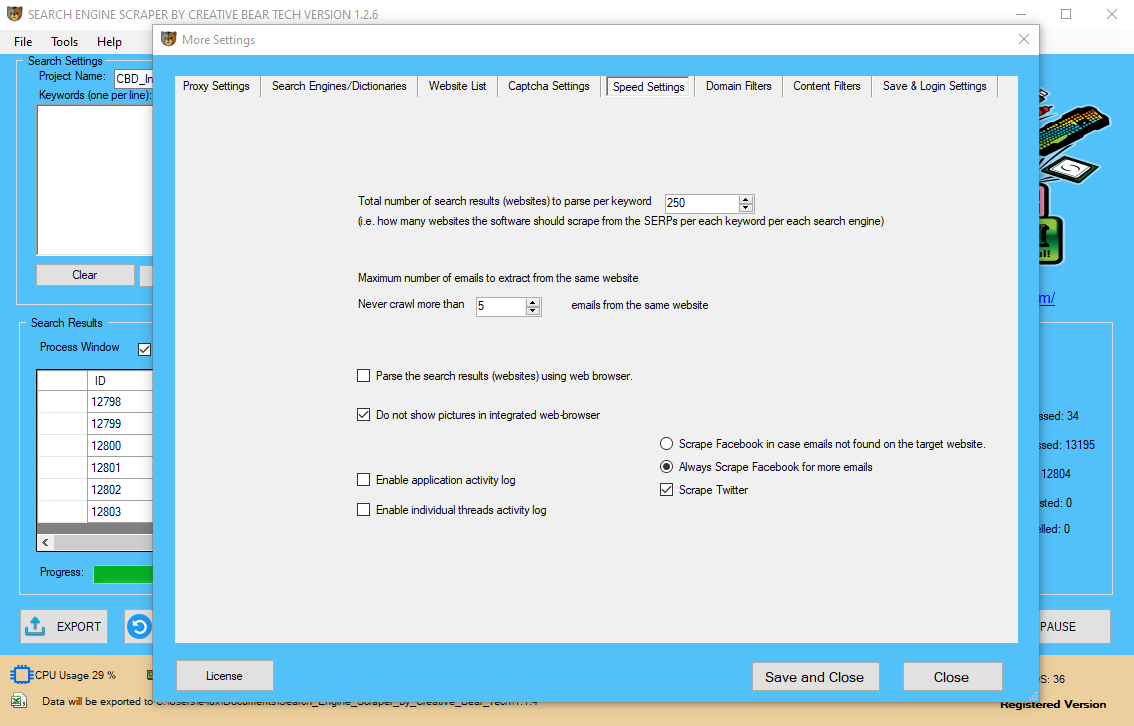
JustCBD CBD Bath Bombs & Hemp Soap - CBD SkinCare and Beauty @JustCbd https://t.co/UvK0e9O2c9 pic.twitter.com/P9WBRC30P6
— Creative Bear Tech (@CreativeBearTec) April 27, 2020
So, in case you scrape 'facts' from the work, modify it and present originally, that's legal. Now, since we have all of the ingredients to prepare the scraper, we must always make a GET request to thetarget URLto get the uncooked HTML data. If you are not acquainted with the scraping device, I would urge you to undergo itsdocumentation. Now Since we're scraping an organization page so I even have set “kind”as company and “linkId”as google/about/. The knowledge that LinkedIn holds belongs to the company, inasmuch as it is being stored on their systems. It is value noting that the Ninth Circuit listed numerous different potential legal treatments for businesses in LinkedIn’s place. A lot of people shall be watching developments with great curiosity. The ruling in HiQ v. LinkedIn signifies that judges sooner or later will have extra leeway. It limits the importance of earlier rulings in the Power Ventures and Nosal cases. In those cases, the court was of the opinion that requiring a login earlier than offering entry to knowledge would render it as non-public, not public, information.
ash your Hands and Stay Safe during Coronavirus (COVID-19) Pandemic - JustCBD https://t.co/XgTq2H2ag3 @JustCbd pic.twitter.com/4l99HPbq5y
— Creative Bear Tech (@CreativeBearTec) April 27, 2020
If an internet site has written underneath its ToS that data assortment is not allowed, you risk being fined for internet scraping, as a result of it's accomplished without the proprietor's permission. Also be ready that some data on needed web sites could also be secured (usernames, passwords or entry codes), you cannot gather these data as nicely. In this post, we're going to scrape information from Linkedin using Python and aWeb Scraping Tool. Like many companies at present, they depend on entry to public-facing information to be able to perform. One of the unspoken however very salient questions raised by the case is the place the road between private and non-private data lies. A judge has dominated that Microsoft’s LinkedIn community must enable a third-get together firm to scrape knowledge publicly posted by LinkedIn users. My first experience with iWeb Scraping for a small information extraction task was wonderful. After that, I repeatedly used their internet scraping services Service and I can absolutely let you know that it is the greatest net scraping Services Company I even have worked with!
Sneak Peek Preview of the next update to the search engine scraper and email extractor ???? ???? ????
— Creative Bear Tech (@CreativeBearTec) October 15, 2019
Public proxy support and in-built checker
Integration of TOR browser
Ability to grab business name from Facebook
Download your copy at https://t.co/wQ3PtYVaNv pic.twitter.com/VRAQtRkTTZ
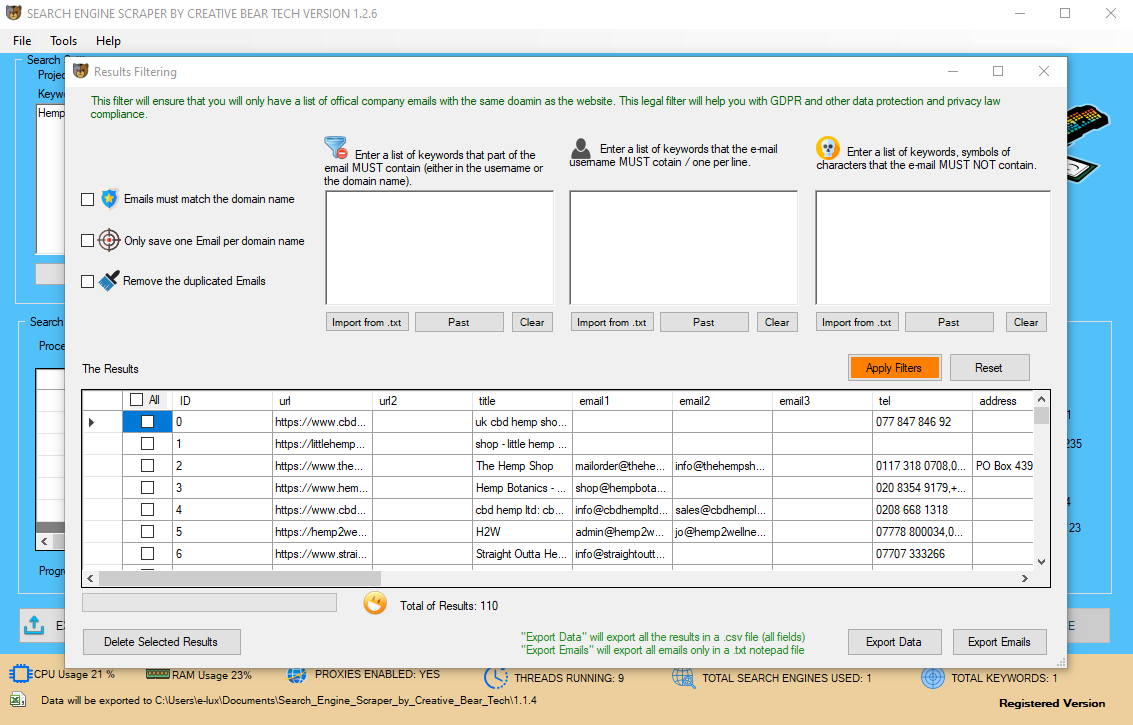 We offering best-price internet scraping, information extraction, information scraping providers, and developing net crawler, internet scraper, net spiders, harvester, bot crawlers, and aggregators’ software program. More than seven hundred+ clients worldwide, from the USA, UK, Canada, Australia, Brazil, Germany, France, etc. Web Scrape provides complicated information extraction by leveraging multiple kinds of web sites. With our net scraping services, we turn unstructured net content into structured and machine-readable, prime-high quality knowledge provides to be consumed on demand. Thankfully, the Ninth Circuit recognized how damaging it would be to increase its prior rulings to publicly available data as with LinkedIn profiles scraped by hiQ. LinkedIn data could be simply extracted by utilizing the services of iWeb Scraping and the information contains the structured and properly-organized data which users can combine into their business actions to provide unique enterprise options. Most of the enterprise customers and other professionals discover LinkedIn data to be very useful for their networking function. For all these customers, LinkedIn knowledge scraping could be completed utilizing a number of the newest and superior knowledge scraping instruments which are available at the 3i Data Scraping.
We offering best-price internet scraping, information extraction, information scraping providers, and developing net crawler, internet scraper, net spiders, harvester, bot crawlers, and aggregators’ software program. More than seven hundred+ clients worldwide, from the USA, UK, Canada, Australia, Brazil, Germany, France, etc. Web Scrape provides complicated information extraction by leveraging multiple kinds of web sites. With our net scraping services, we turn unstructured net content into structured and machine-readable, prime-high quality knowledge provides to be consumed on demand. Thankfully, the Ninth Circuit recognized how damaging it would be to increase its prior rulings to publicly available data as with LinkedIn profiles scraped by hiQ. LinkedIn data could be simply extracted by utilizing the services of iWeb Scraping and the information contains the structured and properly-organized data which users can combine into their business actions to provide unique enterprise options. Most of the enterprise customers and other professionals discover LinkedIn data to be very useful for their networking function. For all these customers, LinkedIn knowledge scraping could be completed utilizing a number of the newest and superior knowledge scraping instruments which are available at the 3i Data Scraping.
From LinkedIn’s perspective, their ToS prohibited the use of automation tools. They had a right to enforce those ToS by banning IP addresses associated with scraping. HiQ is a knowledge analytics firm that provides business intelligence based on publicly-out there knowledge scraped from LinkedIn. With a rising number of entities scraping LinkedIn for data, the platform took motion to terminate the accounts of suspected offenders. They had been in a position to easily circumvent the IP ban, by using proxy companies to masks the IP addresses they used for scraping. It’s actually onerous to get an organization which might offer internet scraping, net knowledge extraction, screen scraping, and display screen scraper work with really high velocity & accuracy. Partly given its procedural posture, hiQ stops wanting establishing a per se rule that scraping of public information doesn't violate the CFAA’s “without authorization” provision. However, hiQ definitely supports the view that scraping such knowledge just isn't a CFAA violation. The court held that hiQ had shown a chance of success on the deserves of this claim, in addition to its CFAA claim. It shall be interesting to see whether or not different scrapers comply with hiQ’s lead in asserting tortious interference with contract claims towards companies that try to stop their scraping actions. If some information isn't allowed to be used for commercial purposes because of copyright, you need to steer clear from it. However, if the scraped data is a creative work, then often just the way in which or format by which it is offered is copyrighted. However, the information itself consists only of what different individuals have submitted to LinkedIn. At the time of the case, the information was accessible to anybody who visited LinkedIn. From HiQ’s perspective, this meant that the data on LinkedIn was truthful sport for scraping. Web Scrape’s Stock Market and Financial Data Scraping providers provide inventory market information from their websites and directly thought API. Our custom net crawlers used for monitoring several stock market websites to maintain observe of world monetary information. This is an especially essential holding that limits the errors within the Ninth Circuit’s earlier rulings in Nosal II and Power Ventures. The court says that those earlier cases control in situations where authorization is usually required—as a result of data just isn't public—and the website proprietor both revokes that authorization or never provides it within the first place. In the case of the appellant presently before the 9th Circuit, hiQ Labs is an information science firm that develops tools to help corporate HR departments maintain tabs on their workforces. Included within the info hiQ provides to its shoppers is data scraped from their employees Data Scraping’ public LinkedIn profiles. On May 23, 2017, LinkedIn despatched hiQ a cease and desist letter demanding that they stop the apply. Two weeks later, hiQ filed a lawsuit in the Northern District of California, asking the court for a declaratory judgment that scraping LinkedIn’s knowledge was lawful. LinkedIn is knowledgeable web site that present very important information about any business personnel. The information could possibly be easily scraped by the services of 3i Data Scraping for business users that want this knowledge to get scrapped from LinkedIn web site. The information contains properly-organized and structured knowledge that users can in corporate into the enterprise activities for producing distinctive business solutions. The knowledge output is generally in display output formats and is user-friendly. 3i Data Scraping provides the Best LinkedIn Web Scraping Services scrape or extract LinkedIn Profile and Company Data. The scraping process usually entails extracting and amassing information from LinkedIn pages and profiles and saving that knowledge in one display screen output type that may be very easy for users to learn and understand. Integrate data into your corporation activities to produce unique business solutions. Unless the decision is outmoded on rehearing before the Ninth Circuit or on attraction to the U.S.
From The Course:
But the courtroom depends on a very narrow interpretation of public data that may not maintain up in practice. Once somebody logs on to Facebook, for example, a wealth of “personal” information is on the market to each person of the service, making this information essentially publicly available. And, as we pointed out in these earlier instances, if a consumer grants a third party access, the third party has a form of authorization, even if the website itself would prefer the third get together not have entry. In any case, if authorization activates whether or not or not somebody has to log in to a free service, then this incentivizes a transfer to shield public data behind a log-in page. First, our team of seasoned scraping veterans develops a scraper unique to your project, designed specifically to focus on and extract the info you need from the websites you need it from.